


Mastering DITA Topics: A Beginner's Guide to Structured Content
Learn the Key Topic Types and How to Build Your First DITA Map


Ever struggled to make your documentation reusable, scalable, and future-proof?
DITA offers a structured solution, and today, we’re diving into how to write your first modular content using DITA’s topic types.
In detail, we will learn:
The three basic DITA topic types.
The structure of these topic types.
How to create and generate DITA maps.
Let’s dive right in!
Missed last week’s article? Then please start with it. It will show you how to set up DITA Open Toolkit and XML Mind XML Editor, which we will use in this one.

DITA Topic Types and Their Structure
First of all: What is a topic?
A topic is a unit of information that does not depend on context to make sense. Other than classic books that are read front to back, a topic should provide an answer to the reader’s question, without the need to read an entire chapter.
Topics are typically as large as one page on a digital screen to avoid scrolling and contribute to scanning.
DITA comes with three different types of topics:
Task
Concept
Reference
Each topic type follows a specific structure defined by DITA’s XML schema (or DTD), ensuring consistency across your documentation.
To understand the next sections better, you should have a basic understanding of how XML works. If you don’t have a foundation, please check out this article.
Topic Type: Task
A Task topic type guides the user with step-by-step instructions.
A good Task topic should not include more than 7 +- 2 steps. Research shows that the average short-term memory can process only this amount of information.
The following code block shows an example of how a Task topic looks. It includes the most frequently used XML tags of a Task.
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE task PUBLIC "-//OASIS//DTD DITA Task//EN"
"task.dtd">
<task>
<title>Installing DITA Open Toolkit</title>
<taskbody>
<prereq>JAVA is installed with a version of at least 17.0.</prereq>
<steps>
<step>
<cmd>Download DITA Open Toolkit from the DITA OT website.</cmd>
<stepresult>The <filepath>dita-ot-4.3.2.zip</filepath> file is added
to your <filepath>Downloads</filepath> folder.</stepresult>
</step>
<step>
<cmd>Extract the <filepath>dita-ot-4.3.2.zip</filepath> file in the
desired location.</cmd>
</step>
<step>
<cmd>Add the <filepath>bin</filepath> folder of the DITA OT
installation directory as a PATH environment variable.</cmd>
</step>
</steps>
<result>DITA OT is installed.</result>
</taskbody>
</task>For more information on the XML tags, please check out this website.
It explains the allowed content, position, and quantity of each tag. I will also explain it in more detail in the video tutorial for my paid members.
And this is what our DITA topic would look like in the default DITA OT PDF layout:

Don’t worry about the layout too much, yet.
We will look into customization later in this series.
Topic Type: Concept
Concept topics describe general concepts to deepen a user’s understanding of the product.
When Task topics answer “How?” questions, the Concept answers “What?” questions.
Concepts must have a purpose. Instead of blindly explaining the ins and outs of your product, start writing your Task topics and then ask yourself this question for each Task:
What knowledge does the user need (and not already have) to complete this task? This question will guide you in writing the right Concepts.
In our Example, DITA OT might serve beginners who are not yet familiar with DITA. A Concept topic should answer the question: “What is DITA?”
Here’s an example of what a Concept may look:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE concept PUBLIC "-//OASIS//DTD DITA Concept//EN"
"concept.dtd">
<concept>
<title>DITA</title>
<shortdesc>A simple explanation of DITA for beginners using bullet
points.</shortdesc>
<conbody>
<p>DITA (Darwin Information Typing Architecture) is a standard for
creating and managing modular content. DITA offers the following features:</p>
<ul>
<li>An XML-based structure for writing technical content.</li>
<li>Topic types such as concept, task, and reference for organizing
information.</li>
<li>Support for content reuse across different documents and
outputs.</li>
<li>Consistency and scalability in documentation, especially for
teams.</li>
<li>Wide adoption in industries that need structured and maintainable
content.</li>
</ul>
</conbody>
</concept>And here’s what it looks like in PDF:

Topic Type: Reference
The Reference is an important type that allows users to quickly look up information, typically in the form of a table.
The most frequent use cases are Datasheets and explanations of software dialogs.
For example, we could use a Reference to explain the options that XML Mind supports on the preference page. We would explain every element that is visible on that dialog.
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE reference PUBLIC "-//OASIS//DTD DITA Reference//EN"
"reference.dtd">
<reference id="xxe-preferences-open">
<title>Preferences: Open</title>
<shortdesc>This table explains the options available under the
<uicontrol>Open</uicontrol> preferences section in XMLmind XML
Editor.</shortdesc>
<refbody>
<table>
<tgroup cols="2">
<colspec colname="option" colwidth="35*"/>
<colspec colname="description" colwidth="65*"/>
<thead>
<row>
<entry>Option</entry>
<entry>Description</entry>
</row>
</thead>
<tbody>
<row>
<entry><uicontrol>Restore previously opened
files</uicontrol></entry>
<entry>Automatically reopens documents that were open during the
last session.</entry>
</row>
<row>
<entry><uicontrol>Open new documents in a new
tab</uicontrol></entry>
<entry>Determines whether new documents open in the same window or
a separate tab.</entry>
</row>
<row>
<entry><uicontrol>Use last used folder</uicontrol></entry>
<entry>Sets the file browser to default to the last location used
to open or save files.</entry>
</row>
<row>
<entry><uicontrol>Enable auto-recovery</uicontrol></entry>
<entry>Creates backup versions of open files to restore in case of
a crash.</entry>
</row>
</tbody>
</tgroup>
</table>
</refbody>
</reference>It might look complex, but don’t worry: Tables in XML can be tricky at first, but tools like XML Mind’s DITA view make the process much easier.
And one more time, the built PDF:

Semantic Inline Elements in DITA
DITA not only determines the structure of its topics. It also provides inline elements. These inline elements give meaning to words.
Instead of formatting words according to how they should look (bold, italic, monospace fonts), you mark them up semantically, i.e., according to their function or meaning.
The most important semantic inline tags in DITA are:
<term>
Identifies words that may have or require extended definitions or explanations.<uicontrol>
Mark up names of buttons, entry fields, menu items, or other objects that allow the user to control the interface.<menucascade>
Documents a series of menu choices. The <menucascade> element contains one or more <uicontrol> elements, for example:
<menucascade> <uicontrol>Start</uicontrol> <uicontrol>Programs</uicontrol> <uicontrol>Accessories</uicontrol> <uicontrol>Notepad</uicontrol> </menucascade><option>
Describes an option that can be used to modify a command (or something else, like a configuration).<keyword>
Any text that has a unique or key-like value. For example, a product name.<filepath>
Indicates the name and optionally the location of a referenced file.<cmdname>
Specifies the name of a command.<apiname>
Provides the name of an application programming interface (API) such as a Java class name or method name.<codeph>
Represents a snippet of code within the main flow of text.
You will notice that all of these elements will be formatted as either bold, italic, or monospace font.
Why even bother differentiating?
First of all, it is much simpler to just name a text as what it is than what it is supposed to look like. The prior contributes to better consistency, especially if multiple authors work on the same document.
With the latter, every author would need to remember how to format text correctly. Very error-prone!
Second, by applying semantics to a text, you allow yourself (or your tool administrator) to process individual texts differently in the future.
Say, you want to add an element or a special link to your API names in the future, instead of just formatting this text in bold. You’d only have to update your stylesheets centrally to process your <apiname> elements differently.
This is not possible when you markup text according to the intended outcome/format.
You set up your documentation for future improvements, without having to touch every single topic by hand.
Binding All Together In a DITA Map
We have structure and we have semantic formatting. The last step is to combine our topics in a meaningful order.
You do this by clustering topics in so-called DITA maps.
A DITA map collects several topics that belong together.
The simplest example of a DITA map is your overall user manual structure. The DITA map would include all of the topics you need in your manual: concepts, tasks, references, you name it.
But DITA maps can go further. You can include DITA maps in DITA maps. This way, you can cluster ideas on a deeper level. Think chapters of a book, and you get the idea.
This is what a DITA map structure may look like:
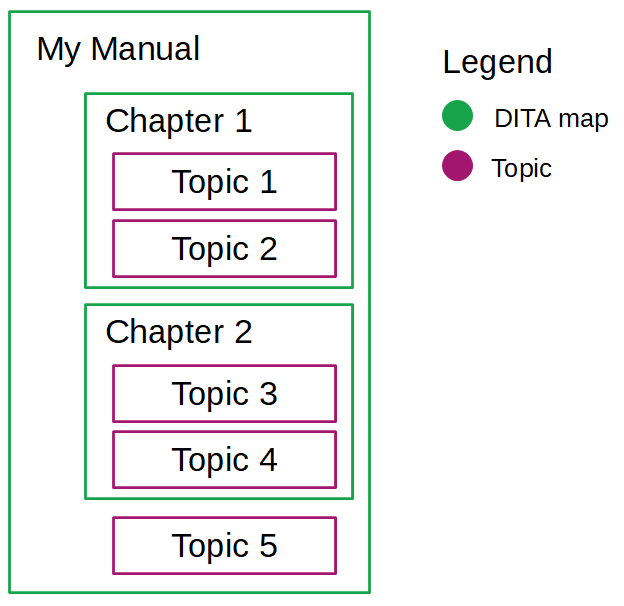
But when you cluster your topics, always remember what a topic actually is: A self-reliant unit of information.
DITA maps are not classic chapters as you would know them from linear books. They do cluster topics, but the topics of the same DITA map must be comprehensive even without the other topics of the same DITA map.
This one requires some practice to get right.
And that’s the DITA basics for you!
I am sure you are eager to try it out yourself now.
For my paid subscribers, check out my detailed guide on how to set up your first document with DITA topics and DITA maps, including detailed instructions and how to do so in XML Mind!
Keep reading with a 7-day free trial
Subscribe to A Linguist's Tech Conquest to keep reading this post and get 7 days of free access to the full post archives.